Analyze massive page 404 issue in PROD
上个周日我们收到大量线上告警,某个关键页面(后续我们以/abc代指)持续404,经过人工重启server之后临时解决了问题,不过这个问题的root cause还没有完全定位到,所以这里只是记录一下问题分析过程。
由于我们前端用的nextjs的dynamic route来生成页面,根据代码实现我们首先怀疑是由于后端API调用出错导致不能成功生成页面,从日志中我们确实发现在告警刚出现的时候有几个超时的请求,通过静态分析和本地重现证实这种情况会导致404,但随着而来的问题是:由于我们有设置revalidate,意味着下一次rebuild page如果能正常访问API就能自行修复404问题,而这些请求只有初期有过超时,后面基本上都是成功返回的,这是怎么回事?
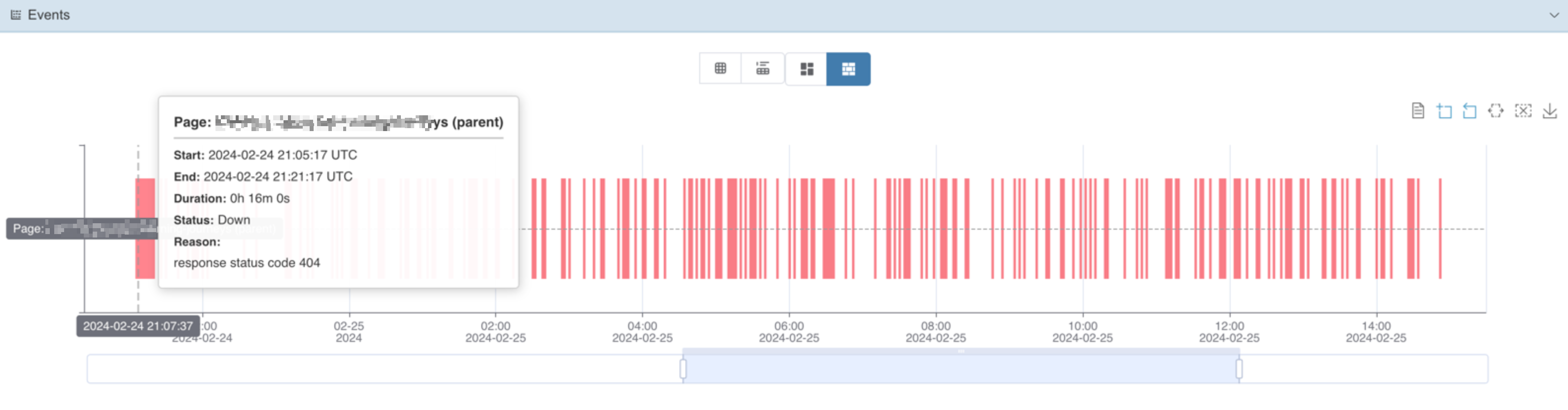
我们先分析了后续请求的失败场景,发现它们都是返回了400状态码,根据日志我们发现后端显示某一个参数多了个/导致不能正常处理,但进一步分析我们发现这种类型的请求/abc/会被重定向到/abc,意味着虽然/abc/页面不会正常生成,但是用户会被自动重定向到正确生成的/abc页面,所以用户是感知不到这个404的,当然这里其实我们是应该对这个slug值做urlencoding处理的。
排除了后端API 400导致的页面无法生成的可能性之后,分析一度陷入僵局,因为这个页面的生成逻辑非常简单,只要能拿到后端的数据基本上就应该能成功返回props。我们意外的发现在告警的这段时间内,/abc返回200的count为1.6K+,而404的count为0.8K+,这意味着确实在后端API恢复正常之后大部分情况下/abc页面是成功返回的,同时这个2:1的比例引起我们注意,因为前端节点一共有3个,我们大胆假设有没有可能其中某一个节点出了问题?
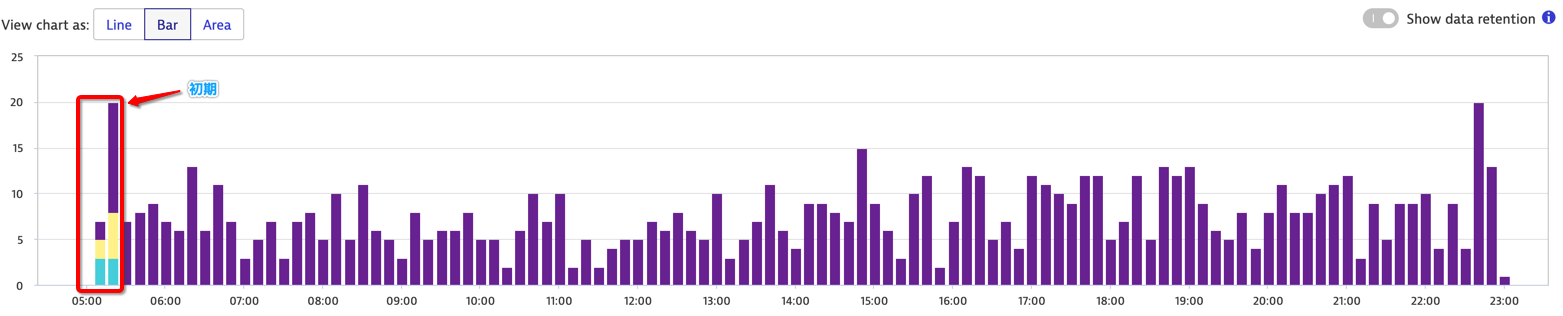
图1是我们在监控系统中对service instance进行分组之后观察到的该页面404 metrics,每一种颜色代表一个instance,我们可以很明显的观察到在告警初期由于API timeout导致的404之后,只有一个instance还在持续404,另外两个已经恢复正常,从而证实了我们的猜想。
锁定了这个instance之后,我们进一步查找了该节点向后端的API请求记录,结果发现从凌晨5点多之后,任何用户访问这个节点的/abc页面都未再触发API请求,也就是说nextjs一直返回缓存的404页面而没有revalidate,我们尝试着在本地重现这个问题,但遗憾的是并没有成功重现,不过也可以理解,毕竟另外两个节点也没有重现该节点的问题。
最后我们猜测是触发了nextjs 13的某个隐藏bug,虽然nextjs社区也有不少人反应revalidate not working的问题,但实际场景跟我们还是或多或少有不一样,所以这一问题暂时只能留下一个问号。