Async Continuation - Understand Flowable Job
Glossary
Job: explicit representation of an operation to trigger process execution, it may have several status like suspended, executable, dead-letter, or serve for different purposes, such as asynchronous task, asynchronous callActivity completion, audit process execution.
TimerJob: job which may trigger in the future, or trigger repeatedly.
AsyncExecutor: flowable concept which is responsible for managing acquisition and execution of jobs.
AsyncHistoryExecutor: like AsyncExecutor, but only history jobs related threads will be managed here. (actually not a must-have)
TaskExecutor: Spring concept, actually the decorator of Java ExecutorService, will be used in AsyncExecutor to execute task.
TaskScheduler: Spring concept, actually the decorator of Java ScheduledExecutorService, will be used in AsyncExecutor to execute periodical task.
Flowable Concepts
Evolution of AsyncExecutor
Flowable posted the evolution to their official blog, here is it: https://www.flowable.com/blog/handling-asynchronous-operations-with-flowable-part-4-evolution-of-the-async-executor
Job Type
From technical perspective, it can be classified to two types: instant jobs and timed jobs. From business perspective of Flowable, instant jobs can be further divided like async job, async history job, external-worker job. From job status perspective, all jobs can be separated into three status: runnable(activated), suspended, dead-letter.
In Flowable, jobs are defined with the following types:
| Types | Description | Lockable | Exclusible | Executable |
|---|---|---|---|---|
| Job | executable async job, used in the following scenarios: * start process asynchronously * activities executed asynchronously * activities triggered asynchronously * SendEventTask activity * ParallelMultiInstance activity * CallActivity marked as completeAsync * EventRegistry event received asynchronously * batch migrate process instance besides the above business usage, async job can also be transformed when: * activate suspended job * re-run dead-letter job * timer job overdue * complete external-worker job |
✅ | ✅ | ✅ |
| TimerJob | delayed or repeated async job, will be used in the following scenarios: * process contains TimerStartEvent * Event Sub-process with TimerStartEvent * Intermediate timer catching event * Boundary timer event * delayed suspend or activate process definition * periodically clean historical process data besides the above business usage, timer job can also be transformed when: * retry async job when possible * activate suspended job which was a timer job originally |
✅ | ✅ | ⛔️ |
| HistoryJob | executable job for only audit process execution in asynchronous mode, the audited info depends on the historyLevel set in configuration | ✅ | ⛔️ | ✅ |
| SuspendedJob | suspended job is actually a job status which is not able to execute directly, will be used in the following scenarios: * set breakpoint when debugging execution * debugging execution exception * when related process instance or process definition is suspended besides the above usage, suspended job can also be transformed when: * suspend async job, timer job or external-worker job |
⛔️ | ✅ | ⛔️ |
| DeadLetterJob | dead-letter job is another job status which is not able to execute directly, only used when executable job failed after retries exhausted. | ⛔️ | ✅ | ⛔️ |
| specific job type for ExternalWorkerTask | ✅ | ✅ | ⛔️ |
Job Finite-State Machine

Job Processing
Job processing can be divided into three phases: 1. job creation, 2. job acquisition, 3. job execution.
While jobs are created during process execution, job acquisition and execution are done by async-executor. The following diagram illustrates these three steps:
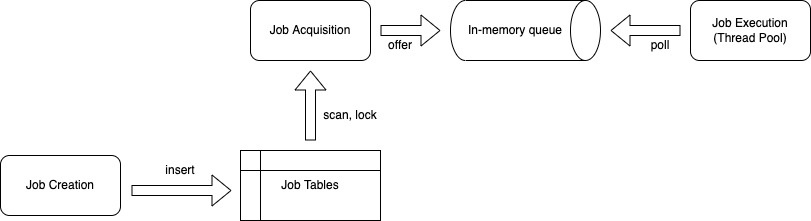
Job Creation
All the scenarios that will create job have been listed above, though there are several kinds of jobs supported in Flowable for different usages, these two fundamental concepts will be touched during job creation: jobHandler, jobType.
JobHandler
Jobs are created for continuous operation, but different jobs may be created for different purposes, for example, some are created to complete CallActivity, some are created for asynchronous ServiceTask, so when these jobs are picked up, executor need to know how to execute these jobs, that’s why JobHandler comes.
Currently Flowable already registered several built-in jobHandlers for above scenarios, and also it’s possible for us to register some customized jobHandlers via processConfiguration, the most typical case could be testing.
JobType
There are four types of job exist in Flowable: message(or maybe we should call it async), timer, externalWorker and historyJob. JobType serves for different purposes as JobHandler during runtime:
- when job sends to dead-letter, the jobType(message, timer, externalWorker, historyJob) will remain unchanged so that it can be correctly rescheduled
- when job suspended, the jobType(message, timer, externalWorker) will remain unchanged so that it can be correctly activated
- when message job retried, it will be converted to a timer job and the jobType will remain as `message` so that it can be correctly executed as a message job afterwards
- when timer job overdue, it will be converted to a message job and the jobType will remain as `timer` so that timer cycle logic can be correctly handled
- when externalWorker job needs to be executed, it will be converted to a message job and the jobType will remain as `externalWorker`
One More Thing
Unlike Flowable, Camunda introduced priority concept for job, job priority is typically used for scheduling jobs, it’s especially useful when executor is in a high-load, higher priority jobs will be guaranteed to be acquired and executed quicker. For more information, please visit: https://docs.camunda.org/manual/7.16/user-guide/process-engine/the-job-executor/#job-prioritization
Job Acquisition
Job acquisition is the process of retrieving jobs from the database that are to be executed next. Job executor will schedule several background threads to acquire different types of jobs, for async(message) jobs and history jobs, they will be offered to the working queue once acquired, but for timer jobs, they will first be converted to async jobs if overdue and later picked up as async job.
Two Phases of Acquisition
Job acquisition has two phases. In the first phase the job executor queries for a configurable amount of unlocked jobs. If at least one job can be found, it enters the second phase, locking the jobs. Locking is necessary in order to ensure that one job can only be acquired by a single job executor instance.
In Flowable implementation, two mandatory fields: lockOwner and lockTime are introduced for locking jobs.
- LockOwner: indicates who is currently locking the job, by default is an unique id for job executor instance
- LockTime: indicates when the lock will be expired in case the original executor instance is crashed or shutdown improperly, by default the value is one hour
Acquisition Orders
As mentioned before, Flowable does not support orders for job acquisition, we have to order jobs in memory if we want to solve job starvation issue in some extreme case.
Error Handling for Acquisition
Jobs could be acquired by different job executor instances simultaneously, in this case, Flowable uses optimistic lock mechanism to solve concurrent acquisition issue, those who failed with optimisticLockException will give up current acquisition cycle and move to next acquisition cycle later. The working mechanism behind this is a revision field which will increased if any updates happened to current record.
We all know that there is a working queue to store acquired async jobs in memory to improve throughput, however, the queue size is not unlimited, if the acquisition rate is much faster than execution rate, then the queue will soon get fulfilled, jobs will be rejected in this case, all rejected jobs needs to be unacquired as soon as possible so that they can be picked up by other instances.
Besides job rejection, the instance itself may be terminated during the time interval between acquisition and execution, if the executor shutdown gracefully, then those unhandled jobs will get unlocked when shutting down. However, if the executor did not shutdown properly for example the instance is crashed, which means there may be some unlocked jobs, if the instance can restart successfully and the uuid of executor kept unchanged, the executor will unlock these jobs when starting, but if the instance failed to restart, these locked jobs cannot be re-acquired until the lock is timed out, job executor will schedule some threads to reset these expired jobs.
Optimization for Acquisition
In Flowable conception, jobs and timer jobs which are stored in their own tables may get updated by different executor instances. According to their experiments, concurrency on the tables was the number one cause of performance degradation, which means even the classic data sharding solution did not give a satisfying result. For more information, please goto this section: Sharding Side-Track.
Global Acquire Lock

This functionality is part of Flowable 6.7.0 and properly the most difference against previous generation. Executor uses this to guarantee that only one executor instance at a time can acquire jobs.
After enabling global lock, jobs can be acquired and locked in bulk instead of one by one and optimistic lock exception is not a worry any more, database table concurrency is also decreased drastically which will help improve the performance a lot. Compared to the solution of sharding data, the global acquire lock is easy to be implemented.
In-memory Trigger
As we know that job executor can be configured to be activated when process engine starts, which means the job executor is accessory with process engine. If the job is created in a node with active job executor, the job will be inserted with lock info so that it cannot be acquired by other instances and add current job to the working queue. This will reduce the time cost for job acquisition, timer job cannot benefit from this as most of them is supposed to be executed in the future.
Job Execution
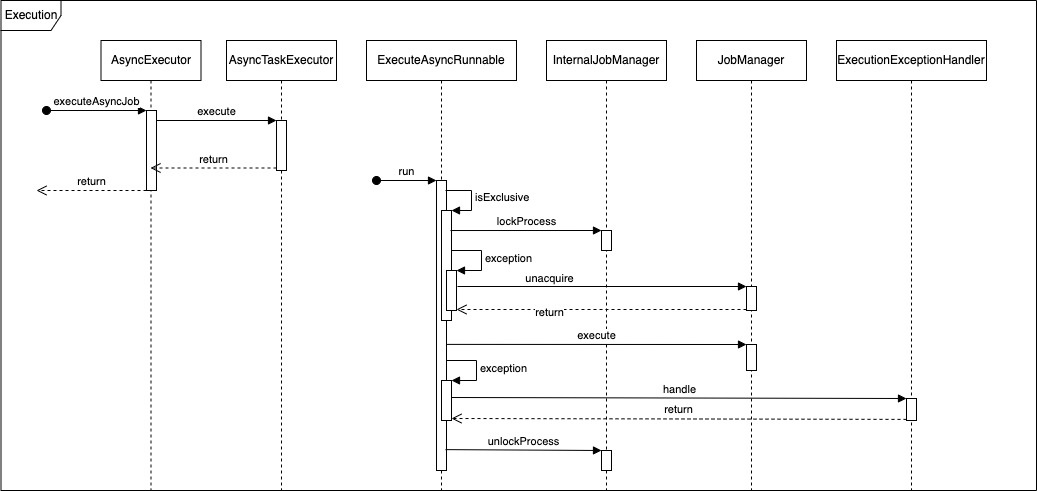
Task Executor
Jobs will be submitted to Flowable AsyncTaskExecutor when executing, in legacy implementation the AsyncTaskExecutor will internally initialize the thread pool with java.util.concurrent.ThreadPoolExecutor, after adopted with Spring since 3rd generation, a new implementation SpringAsyncTaskExecutor was introduced, which allows to inject a reusable TaskExecutor.
Error Handling
Jobs could fail during execution time, for example, if a serviceTask throws exception. Flowable provides default execution exception handler while it’s also possible to do customization via configuration, the underlying default implementation for job and history job is slightly different.
For job, the default implementation will convert the failed job to a timer job with the retries decreased and will be scheduled in the near future, if the retries is exhausted the job will be send to dead-letter and never get handled by executor unless rescheduled manually.
For history job, Flowable will not convert it to a timer job, instead if the retries is not exhausted Flowable will copy all the job info to new one with lockOwner and lockTime erased, otherwise the history job will be send to dead-letter. New created history job will be acquired by executor and waiting in working queue for next pick up.
Concurrent Execution
We know that job is a representation of async operation to trigger process execution, which means jobs will be tied with a process instance, take the following process definition as an example:
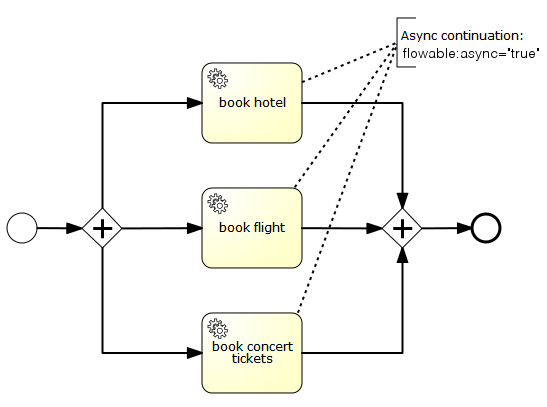
Here we have a parallel gateway followed by three service tasks which all perform an asynchronous continuation. As a result of this, three jobs will be added to the database and later picked up by job executor(maybe different one in clustered case), job executor will delegate the runnable to task executor which means these three jobs could be executed concurrently.
Concurrent is usually a good thing for performance improvement, however it may also bring some inconsistency issue. In this case when one serviceTask job is completed, we arrive at the parallel join, we need to decide whether we can move on or wait for other branches completed. As these three jobs are all asynchronous, which means the check points for each job we mentioned before are in different transactions, if each transaction assumes that it has to wait for the other ones, none will continue the process after the parallel join and the process instance will remain in that state forever:
- txA.begin, `book hotel` execution inactivate(completion), inactiveExecution.size == 1 while incomingSequenceFlow.size == 3, CANNOT proceed
- txB.begin, `book flight` execution inactivate(completion), inactiveExecution.size == 1 while incomingSequenceFlow.size == 3, CANNOT proceed, txB.commit
- txC.begin, `book concert tickets` execution inactivate(completion), inactivateExecution.size == 2 while incomingSequenceFlow.size == 3, CANNOT proceed
- txA.commit, txC.commit
Flowable uses optimistic lock mechanism to do synchronization between different transactions within same process instance, if multiple executions arrive at the parallel join concurrently, they all assume that they have to wait, increment the version of their parent execution (the process instance) and then try to commit, first commit first win, others will fail with optimistic lock exception and retry later, things will be:
- txA.begin, `book hotel` execution inactivate(completion), parentExecution.revision = 2(previous revision 1), inactiveExecution.size == 1 while incomingSequenceFlow.size == 3, CANNOT proceed
- txB.begin, `book flight` execution inactivate(completion), parentExecution.revision = 2(previous revision 1), inactiveExecution.size == 1 while incomingSequenceFlow.size == 3, CANNOT proceed, txB.commit
- txC.begin, `book concert tickets` execution inactivate(completion), parentExecution.revision = 3(previous revision 2), inactivateExecution.size == 2 while incomingSequenceFlow.size == 3, CANNOT proceed, txC.commit
- txA.tryCommit, parentExecution previous revision: 1 does not match current db revision: 2, txA fails with optimistic lock exception
- job retries later: txD.begin, `book hotel` execution inactivate(completion), parentExecution.revision = 4(previous revision 3), inactiveExecution.size == 3 while incomingSequenceFlow.size == 3, CAN proceed, txD.commit
Exclusive Job
Optimistic lock is a perfectly fine solution to solve inconsistency issue, however, it might not always be a desirable behavior since:
- Job retry is not unlimited, by default is 3, if the forks’ async job failed for too many times, they will be stay in dead-letter and never picked up automatically
- Task delegated behavior may not share the same transaction boundary with task, for example, the task may do a remote call and not able to be rollbacked by activity failed transaction
Here exclusive job comes, when the job starts to run, the first thing is to check whether the job is exclusive, the exclusive here doesn’t mean the job itself needs to be exclusive though Flowable itself even named it as lockJob, actually if the job is exclusive, then it will try to lock the process instance and if locked successfully all other exclusive jobs for the same process instance won’t be executed concurrently which ensures sequential execution.
Exclusive is by default turn on for job and timer job, but not supported for history job as history job cannot be associated with a runtime process instance.
MessageQueue Based AsyncExecutor
Message-queue based async executor is designed to omit the acquisition phase of instant job processing.
When a new async job is created, a message containing the job identifier will be sent to message queue (in a transaction committed transaction listener, so we’re sure the job entry is in the database). A message consumer then takes this job identifier to fetch the job and execute the job, thus executor will not create a thread pool for instant jobs anymore. (I think that’s why the instant job is also named as `message` type)
BPE Extension
Before we dig into the extension that BPE did for job runtime, we need to first keep it in mind that BPE is an embedded engine in BizX, the multi-datasource routing of HANA is configured in client(BizX).
AsyncExecutor
The AsyncExecutor of activiti 5.21 is the second generation, it is responsible for: 1) scheduling job and timer job acquisition task, 2) execute jobs with thread pool.
Job Acquisition
The default behavior of job acquisition is not aware of underlying persistence layer, thus only two threads(one for async job acquisition, another for timer job acquisition) are managed in the AsyncExecutor, it will definitely not work for BPE. Actually, there are several options for BPE to do acquisition:
- one shared acquisition thread, do dbPool switch in the thread
- one tenant one thread, manage the lifecycle of these threads in the AsyncExecutor
- one dbPool one thread, manage the lifecycle of these threads in the AsyncExecutor
The option1 uses the least resource, but it may encounter efficiency issue if thread blocks too much time for one or more dbPool, thus it makes sense to partition the job acquisition by tenant, then option2 comes.
However, option2 will consume more thread resource if the tenant amount grows larger, it’s not a good idea to do so.
The tenants may increase, but the dbPool is relatively fixed, then option3 seems a better choice than option2, I think that’s why BPE chooses it at last. Briefly speaking, BPE initializes job acquisition thread for each dbPool when AsyncExecutor starts and terminates those threads once the AsyncExecutor stops, each acquisition thread takes responsibility for its own dbPool.
Job Execution
Jobs need to be executed once acquired, AsyncExecutor will use a thread pool to schedule those acquired jobs, again BPE as an embedded engine in BizX, needs to set up the context to run the job and destroy it after job completed, that’s exactly why SFExecuteAsyncRunnable overrides activiti default runnable.
Potential Issues
We all know that BPE deployed job cluster separately in production environment, that will cause two main issues: 1) job added hint never works, 2) no sharding for job acquisition.
Let’s first take a look at issue1 - job added hint not work, in the default activiti behavior, if AsyncExecutor is activated in the engine instance, any executable jobs which are added there will be immediately locked and executed, which will omit the step of acquisition. According to the performance benchmark of Flowable 6.7, the acquisition is the bottleneck of job runtime, deploy a single job cluster won’t be a recommendation.
And then see the issue2 - no sharding, as the acquisition have two phases, which are scan and lock, each node in the same job cluster may do acquisition from same schema, which may result to concurrent acquisition issue.
Acitiviti engine itself acquired the job one by one with optimistic lock check by default, but this will definitely impact the throughput in general.
Though we can increase the job acquisition size, the chance of collision will be high, which means optimistic lock exception will happen frequently, what’s more, as the concurrency keeps increasing, the database table response time may become much longer.
At last, you may find that HistoryJob and AsyncHistoryExecutor is not presented here, the reason is that async mode of auditing historical data is not introduced in this generation yet.
Open Question
- Is correlationId same concept as businessKey? - Actually this column is used to link jobs that get re-created due to retry, scheduled and so on, as it will delete original job entity in the DB and re-insert a record with new id, thus correlationId is used to store the before uuid.
References
- Demystifying the Asynchronous Flag
- Demystifying the Asynchronous Flag (II)
- Handling asynchronous operations with Flowable – Part 1: Introducing the new Async Executor
- Handling Asynchronous Operations with Flowable – Part 2: Components & Configuration
- Handling Asynchronous Operations with Flowable – Part 3: Performance Benchmarks
- Handling Asynchronous Operations with Flowable – Part 4: Evolution of the Async Executor
- Asynchronous History Performance Benchmark
- Camunda - The Job Executor
- Flowable Advanced - Async Executor