Analyze Deadlock in Activiti/Flowable
What is Deadlock?
Most of us should hear about deadlock in operating system for the first time, it’s a situation when several processes hold and wait for more resources mutually, there are four prerequisites:
- Mutual exclusion
- Hold and wait
- No preemption
- Circular wait
Hence, deadlock is usually handled by preventing one of the four conditions listed above, the major approaches are as follows:
- Deadlock avoidance
- Deadlock prevention
- Deadlock detection
Deadlock avoidance looks similar to prevention, but they actually handle deadlock in different ways. Deadlock Prevention works by preventing any one of the four conditions from occuring, while Deadlock Avoidance works by analyzing if the system is safety when allocating resources, the most famous deadlock avoidance algorithm is Banker’s Algorithm. Deadlock Detection allows deadlock to occur, but it will detect the system state to check if there is deadlock, once deadlock detected, it will abort one of more involved processes. Despite process termination, other systems may use resource preemption to break the deadlock.
Deadlock in Database
Deadlock Detection is widely used in database system, it tracks resource allocation and transaction state, if deadlock is detected, it will rollback and restart one of the transactions in order to break the cycle. Here we will use MySQL InnoDB as the target database system, and investigate the root cause of deadlock in database.
Transaction in MySQL InnoDB
When we talk about DB transaction, we all know that it is used to group several statements to perform atomically, there are four properties of transaction as atomicity, consistency, isolation and duration. Here we need to understand more about transaction isolation level, as transaction can be either a read transaction or a write transaction, different isolation level will make transaction behave differently. As described by SQL:1992 standard, there are four isolation levels:
- Read uncommitted - the lowest isolation level, it allows dirty read which means a read transaction can see the not-yet-committed changes made by other transactions
- Read committed - stricter than the above one, a read transaction can only see committed changes made by others, however it doesn’t guarantee the same data will be consistent when reading repeatedly as other transaction may commit data change concurrently
- Repeatable read - to avoid non-repeatable read as described above, but this level doesn’t guarantee data consistency when write transaction doing insert or delete concurrently which is known as phantom read
- Serializable - the strictest isolation level, even phantom read is not allowed, read transaction and write transaction shall execute in serial
Obiviously isolation levels define the behaviors of read transaction, but actually when implementing UPDATE and DELETE statement with conditions, they are also slightly affected with different locking strategy, we will discuss it in the next paragraph. Here we will focus on two important kinds of read in MySQL InnoDB: 1) consistent non-locking read; 2) locking read. And how they are implemented in InnoDB.
-
Consistent Non-locking Read: it is based on MVCC and does not acquire lock but reads a snapshot based on the version of current transaction. In read committed, each read within the same transaction will get its own snapshot while repeatable read will get the snapshot established by the first read for other same reads within the transaction. In this case, unrepeatable read and phantom read are both avoided when using repeatable read, but here note that even SELECT statement follows consistent read, UPDATE and DELETE statement behave differently, once another transaction committed the changes to some rows that current transaction updated or deleted, those changes will be visible to current transaction.
-
Locking Read: it will acquire necessary lock by using sql like
SELECT ... FOR UPDATEandSELECT ... LOCK IN SHARE MODE, the former will acquire exclusive lock while the latter only requests shared lock so that other read transactions can also perform select, if you don’t want the statement to be blocked, you can add NOWAIT or SKIP LOCKED at the end. In read committed, it will acquire record lock on matching records, but gap lock is not acquired and phantom row problem may occur. In repeatable read locking depends on the search condition, gap lock or next-key lock may need if it’s not a unique search with a unique index. In serializable isolation level simple SELECT statement will be automatically converted to shared blocking read when autocommit is disabled.
Locking in MySQL InnoDB
Lock is used to provide data consistency in concurrent computing, based on different types of object to be locked, there are three typical granularities of lock:
- Table lock - lowest lock overhead but minimum concurrency
- Page lock - page is the storage unit of underlying file system, used in MySQL BDB engine
- Record lock - or known as row lock, the finest granularity of lock
Table locks in InnoDB can be divided into three types: 1) explicit table lock; 2) intention lock; 3) AUTO-INC lock. Explicit table lock can be acquired and released with statement LOCK TABLES...(READ/WRITE) and UNLOCK TABLES. Intention lock will be implicitly acquired when you performing locking read or INSERT/UPDATE/DELETE, note that only SELECT ... FOR SHARE will acquire intention shared lock and others will acquire intention exclusive lock. AUTO-INC lock is used when doing insert with auto increment columns, however, this lock is different than others, it’s a short-lived lock and may release ASAP instead of transaction end. These table locks compatibility can be summarized as:
| request\hold | S | X | IS | IX | AUTO-INC |
|---|---|---|---|---|---|
| S | ✅ | ⛔️ | ✅ | ⛔️ | ⛔️ |
| X | ⛔️ | ⛔️ | ⛔️ | ⛔️ | ⛔️ |
| IS | ✅ | ⛔️ | ✅ | ✅ | ✅ |
| IX | ⛔️ | ⛔️ | ✅ | ✅ | ✅ |
| AUTO-INC | ⛔️ | ⛔️ | ✅ | ✅ | ⛔️ |
Row locks in InnoDB can be simplified into: 1) record lock, which is shorted as REC_NOT_GAP, typically used for unique search condition on a unique index; 2) gap lock, a lock on the gap between index records, can co-exist with no matter shared or exclusive, typically used when it’s a range search condition or the index is not a unique one; 3) next-key lock, which is actually a combination of record lock and gap lock, depends on whether the range search is inclusive; 4) insert intention lock, another kind of gap lock, used when doing insertion, cannot co-exist with gap lock. These record locks compatibility can be given as a matrix as well:
| request\hold | S, REC_NOT_GAP | X, REC_NOT_GAP | *, GAP | S (next-key) | X (next-key) | *, INSERT_INTENTION |
|---|---|---|---|---|---|---|
| S, REC_NOT_GAP | ✅ | ⛔️ | ✅ | ✅ | ⛔️ | ✅ |
| X, REC_NOT_GAP | ⛔️ | ⛔️ | ✅ | ⛔️ | ⛔️ | ✅ |
| *, GAP | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| S (next-key) | ✅ | ⛔️ | ✅ | ✅ | ⛔️ | ⛔️ |
| X (next-key) | ⛔️ | ⛔️ | ✅ | ⛔️ | ⛔️ | ⛔️ |
| *, INSERT_INTENTION | ✅ | ✅ | ⛔️ | ⛔️ | ⛔️ | ✅ |
Here are some points need to pay attention:
- the compatibility matrix is asymmetric, to be more specific, insert intention lock has to wait for gap lock but gap lock doesn’t need to wait for insert intention lock
- a shared lock on the index record will be acquired when duplicate key error occurs, which could result in deadlock in some extreme case, for example: if table t_test contains value id=1, SessionA begins tx and delete id=1, SessionB begins tx and insert id=1, SessionC begins tx and insert id=1, SessionA will held a exclusive record lock for id=1, SessionB and SessionC will both waiting for a shared record lock on id=1 as they are faing duplicate key error, after SessionA commits tx, there will be deadlock because SessionB and SessionC are holding shared record lock and trying to request exclusive record lock on id=1
- if a unique secondary index is used, matching primary index record will also be locked (which differs from the conclusion from [10])
- if UPDATE modifies primary index records, implicit shared record locks on affected secondary index records will be held
- a next-key lock will be acquired when the search condition does not fully qualified the using composite index
- foreign key constraint will acquire shared record lock on those records to be checked when performing INSERT/UPDATE/DELETE
Deadlock in Activiti/Flowable
Finally, we come to our topic, deadlock is a known issue for Activiti and forked projects like Flowable and Camunda, here is Activiti issue, Camunda issue, Flowable issue. We also received several jira issues regarding deadlock like PFS-7154, PFS-9367.
To be frank, it’s hard to list cases or patterns for all the deadlocks in these workflow engines, even we narrow down the scope to one workflow engine, they may have different tables, columns, indexes, constraints among different versions, not to mention different underlying database systems use different locking strategy when performing DML/DDL, I would recommend to take a look into the deadlock graph to figure out the exact root cause when facing such kind of issue in production, here I will take Flowable 6.7 and MySQL8.0(innoDB engine) as example.
Let’s first have a brief look of the implementation of Flowable 6.7(the relevant code doesn’t vary a lot from Activiti and Camunda) We all knew that the underlying persistence layer for Flowable is MyBatis, to reduce unnecessary write and read operations to DB, Flowable provided DbSqlSession to perform CRUD and once the command ended it will flush changed objects to DB when required:
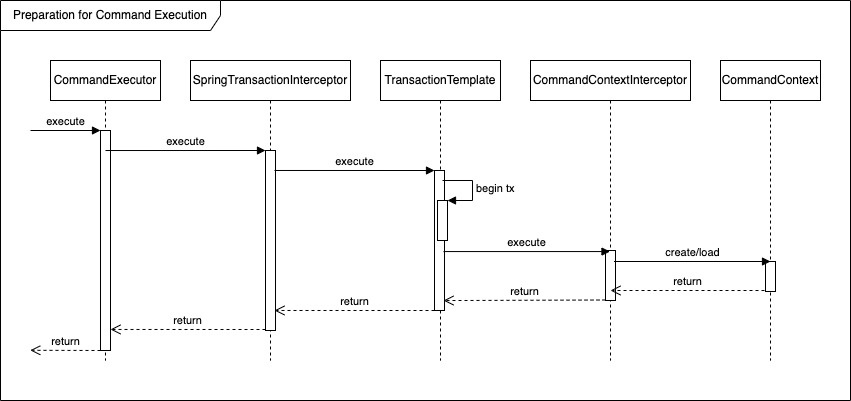
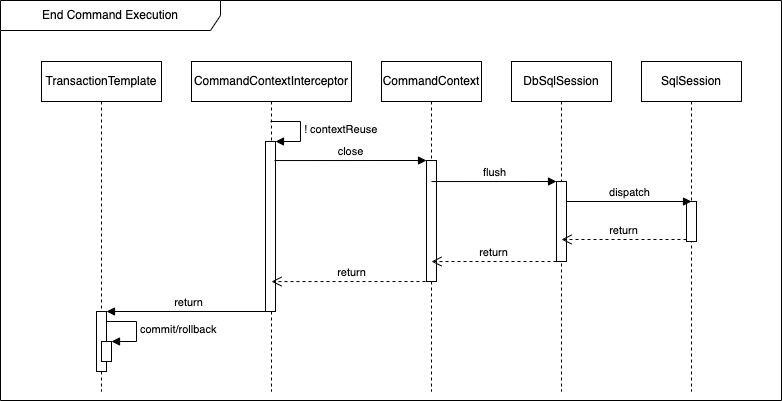
Now take a look at how DbSqlSession interact with MyBatis to execute statements:
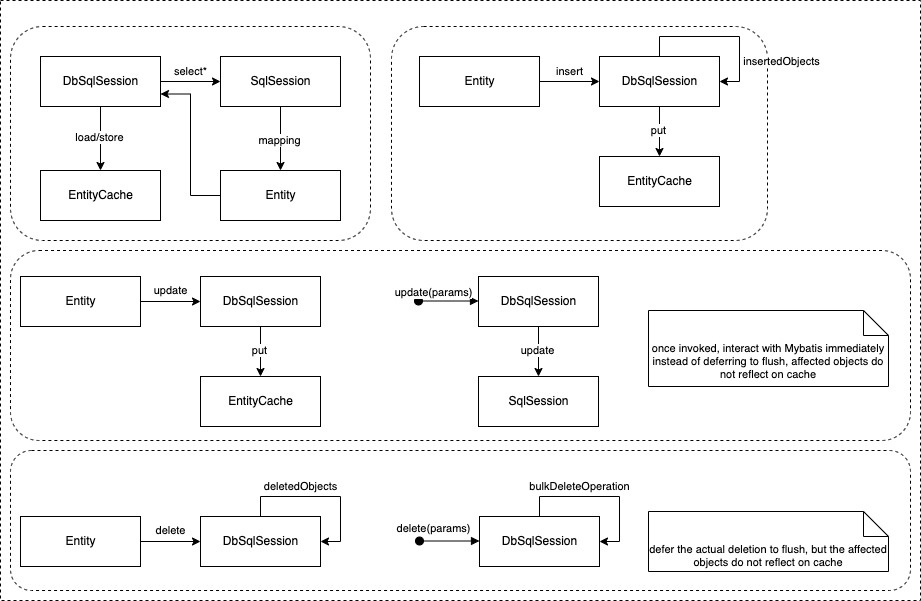
You could find the execution sequence of write statements: 1) update with parameters; 2) insert; 3) update with entities; 4) delete with entities; 5) delete with parameters. BTW, I think it’s a potential defect to defer the No.5 operation, as select could read stale objects which shall be deleted earlier even within the same transaction.
I do believe most deadlock cases are caused by updates/deletes especially updates, the most important thing is the operation order strategy of Flowable:
- for updates, the relative order of entity class may be different as EntityCache is using Class as the key, the hash code for same class is different in different nodes
- for both updates and deletes, Flowable did not sort the entities by id at all, which means different nodes could write same entities in different order and very likely to result in deadlock
What about insert? Flushing inserts is obeying the order of class and time sequence(first insert first flush), and remember INSERT_INTENTION does not block gap lock and other INSERT_INTENTION unless you are inserting same ID_, so it shouldn’t be a main reason for deadlock as well. (Though deadlock could happen in some case, as Flowable is using String as the type of ID, and the value can be self assigned in the code, if txA is inserting Entity1 and txB is inserting Entity2, both succeeded, and then txA try to insert Entity2 while txB try to insert Entity1, then deadlock will occur)
Another two conditional write operations: No.1 - update with parameters and No.5 - delete with parameters, it’s impossible to predict the actual affected rows, so the only way to avoid them from deadlock is restrict the data set and make the operation as simple as possible, for example do not call one command inside another command, add distinctive index for related columns. The good news is that currently the most two typical cases for conditonal updates are: 1) migrate tenant id; 2) update lock info for jobs and process instances. Case1 is rare without doubt, and case2 has two situations, one is clear process instances’ lock when engine shutting down, another is release jobs’ lock periodically, both are cheap operation and the dataset is always restricted to exact lock owner.
Here I didn’t mention select specifically, as select in Flowable is always non-blocking which couldn’t cause deadlock unless you change the default isolation level to serializable.
One Deadlock Example
As I mentioned in the above section, EntityCache is using Class as the key of HashMap, when two or more nodes are performing update/delete on same objects, it will be possible to build a cycle, and the possibility will be larger if more classes involved. (Given two nodes, if three classes involved, it will be 1/6 to have the same order, in another word, 5/6 to have different order, when four classes involved, the possibility will be 23/24)
In my example, I simply invoked dbSqlSession.update in the command, with four classes and each class has 10 entities, run the test code in both gradle and junit to simulate two nodes.
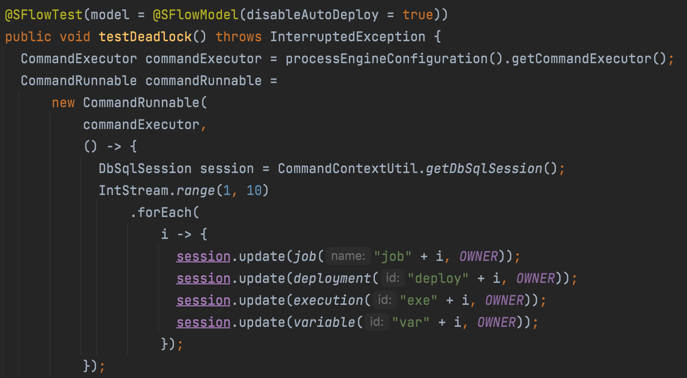
The test result shows that one test succeeded and another failed with deadlock:
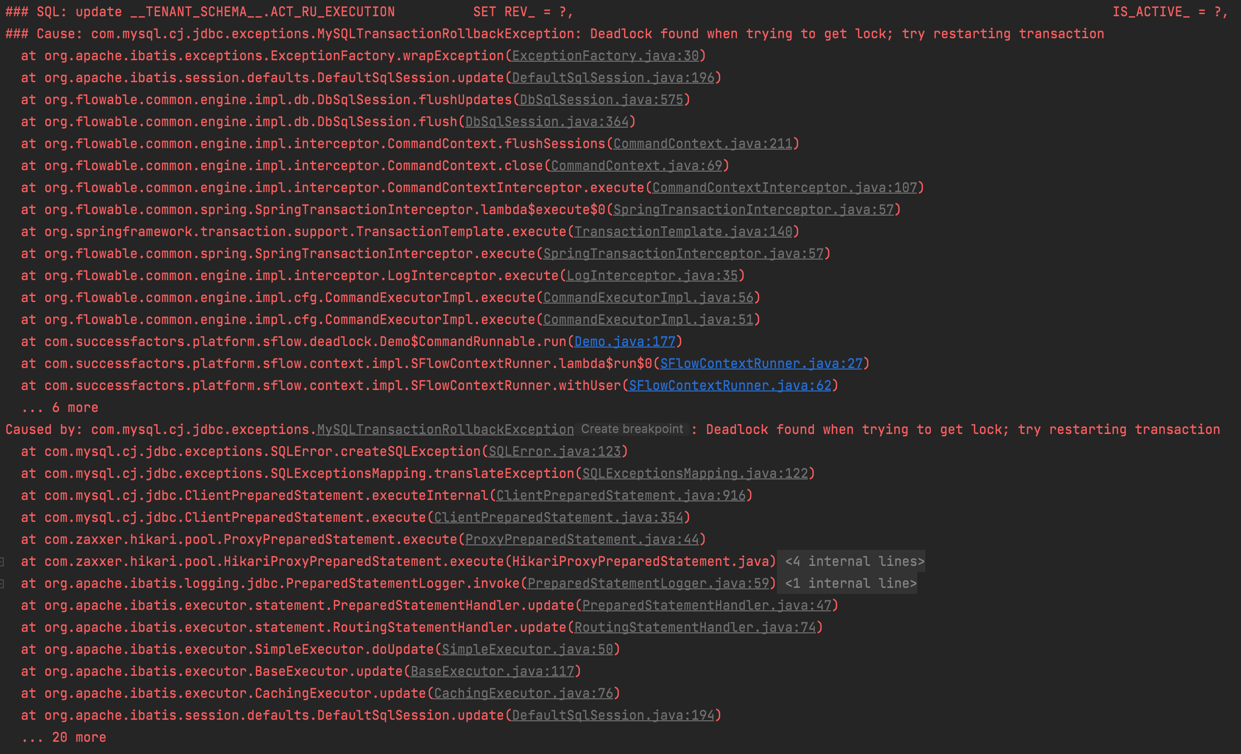
Let’s take a look at the deadlock graph, since I am using MySQL, we can use SHOW ENGINE INNODB STATUS command to show latest detected deadlock details:
*** (1) TRANSACTION:
TRANSACTION 3059, ACTIVE 0 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 4 lock struct(s), heap size 1128, 10 row lock(s), undo log entries 9
MySQL thread id 329, OS thread handle 123145369366528, query id 4634 localhost 127.0.0.1 root updating
/* APPLICATIONUSER=pepsico, APPLICATION=sflow-integration-test */ update PEPSICO.ACT_RU_JOB
SET REV_ = 7,
CATEGORY_ = 'fb8dcb7c-c095-45a0-a9bb-1485f85a72e5',
RETRIES_ = 0
where ID_= 'job2'
and REV_ = 6
*** (1) HOLDS THE LOCK(S):
RECORD LOCKS space id 92 page no 4 n bits 96 index PRIMARY of table `pepsico`.`act_ru_variable` trx id 3059 lock_mode X locks rec but not gap
Record lock, heap no 2 PHYSICAL RECORD: n_fields 17; compact format; info bits 0
0: len 4; hex 76617231; asc var1;;
1: len 6; hex 000000000bf3; asc ;;
2: len 7; hex 01000001001256; asc V;;
3: len 4; hex 80000007; asc ;;
4: len 6; hex 737472696e67; asc string;;
5: len 30; hex 66623864636237632d633039352d343561302d613962622d313438356638; asc fb8dcb7c-c095-45a0-a9bb-1485f8; (total 36 bytes);
Too long, other Record locks on the same table omitted...
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 88 page no 4 n bits 96 index PRIMARY of table `pepsico`.`act_ru_job` trx id 3059 lock_mode X locks rec but not gap waiting
Record lock, heap no 13 PHYSICAL RECORD: n_fields 29; compact format; info bits 0
0: len 4; hex 6a6f6232; asc job2;;
1: len 6; hex 000000000bf2; asc ;;
2: len 7; hex 02000001420823; asc B #;;
3: len 4; hex 80000007; asc ;;
4: len 30; hex 61313136636161332d323565312d346436622d383535662d336537646235; asc a116caa3-25e1-4d6b-855f-3e7db5; (total 36 bytes);
5: len 1; hex 32; asc 2;;
*** (2) TRANSACTION:
TRANSACTION 3058, ACTIVE 0 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 6 lock struct(s), heap size 1128, 19 row lock(s), undo log entries 18
MySQL thread id 349, OS thread handle 123145399185408, query id 4641 localhost 127.0.0.1 root updating
/* APPLICATIONUSER=pepsico, APPLICATION=sflow-integration-test */ update PEPSICO.ACT_RU_VARIABLE
SET REV_ = 7,
NAME_ = 'a116caa3-25e1-4d6b-855f-3e7db5810dc1',
TYPE_ = 'string'
where ID_ = 'var9'
and REV_ = 6
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 88 page no 4 n bits 96 index PRIMARY of table `pepsico`.`act_ru_job` trx id 3058 lock_mode X locks rec but not gap
Record lock, heap no 13 PHYSICAL RECORD: n_fields 29; compact format; info bits 0
0: len 4; hex 6a6f6232; asc job2;;
1: len 6; hex 000000000bf2; asc ;;
2: len 7; hex 02000001420823; asc B #;;
3: len 4; hex 80000007; asc ;;
4: len 30; hex 61313136636161332d323565312d346436622d383535662d336537646235; asc a116caa3-25e1-4d6b-855f-3e7db5; (total 36 bytes);
5: len 1; hex 32; asc 2;;
Too long, other Record locks on the same table omitted...
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 92 page no 4 n bits 96 index PRIMARY of table `pepsico`.`act_ru_variable` trx id 3058 lock_mode X locks rec but not gap waiting
Record lock, heap no 30 PHYSICAL RECORD: n_fields 17; compact format; info bits 0
0: len 4; hex 76617239; asc var9;;
1: len 6; hex 000000000bf3; asc ;;
2: len 7; hex 01000001001016; asc ;;
3: len 4; hex 80000007; asc ;;
4: len 6; hex 737472696e67; asc string;;
5: len 30; hex 66623864636237632d633039352d343561302d613962622d313438356638; asc fb8dcb7c-c095-45a0-a9bb-1485f8; (total 36 bytes);
We could see that tx1 is holding X, REC_NOT_GAP on var1~var9 and waiting for lock on job2, while tx2 is holding X, REC_NOT_GAP on job1~job9 and waiting for lock on var9, which perfectly result in a circular wait status. To fix deadlock in this case is not complex, we just need to keep the order by entity class and entity id, so we can directly re-implement the EntityCache.getAllCachedEntities.
However, this is not the final solution, remember that Flowable is flushing entities by operation(INSERT/UPDATE/DELETE), which means we need to rewrite the strategy of DbSqlSession.flush, this is a big code change and we will have a try in the future.
References
- Deadlock
- Difference between Deadlock Prevention and Deadlock Avoidance
- Isolation(database systems)
- MySQL - Transaction Isolation Levels
- MySQL - InnoDB Locking
- MySQL - Consistent Nonlocking Reads
- MySQL - Locking Reads
- Understand the basics of locks and deadlocks in MySQL
- InnoDB Data Locking - Part 2 “Locks”
- InnoDB Data Locking - Part 2.5 “Locks” (Deeper dive)
- InnoDB Data Locking – Part 3 “Deadlocks”